検索エンジンはどう動く?知りたい情報が表示されるまでの仕組みを初心者向けに整理
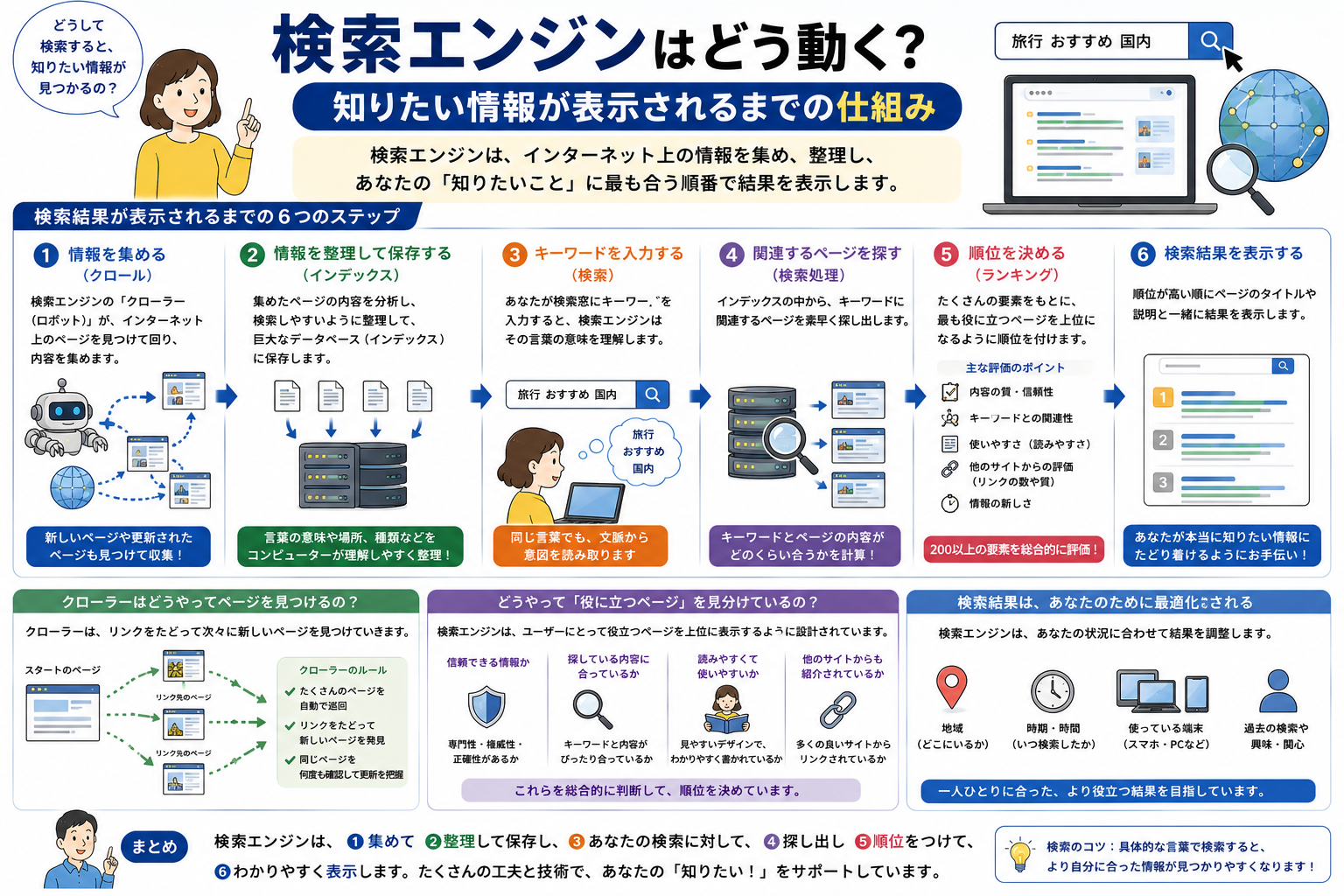
検索エンジンは、ネット上のページをその場で全部読んでいるわけではありません。あらかじめ集めて整理した巨大なデータベースから、検索語に合う候補を選び、並べ替えて表示する仕組みです。
つまり流れは大きく3段階です。ページを見つける、内容を整理して登録する、検索語に合わせて結果を出す。この順番で動くから、数秒どころか一瞬で結果を返せます。
- 先に結論: 検索エンジンの基本は「クローリング」「インデックス」「ランキング」の3工程
- すぐ出る理由: 毎回ゼロから探すのではなく、事前に作った索引を使うから
- 結果が人によって違う理由: 検索語だけでなく、場所、言語、端末、検索意図も見ているから
- 重要な注意点: 公開されているページでも、必ず見つかる・登録される・上位表示されるとは限らない
結局どういう仕組みなのか
2026年5月4日時点で確認できるGoogle公式資料では、検索は「クローリング」「インデックス」「検索結果の提供」の3段階で説明されています。Bingの公式説明も大枠は同じです。
ここがポイント: 検索エンジンは「インターネット全体をその場で探す道具」ではなく、「先に集めて整理しておいた情報から、今の検索に合うものを選び直す道具」です。
この理解があると、なぜ新しいページがすぐ出ないのか、なぜ同じ言葉でも人によって結果が違うのかが見えやすくなります。
全体像: 検索エンジンは巨大な図書館の案内係に近い
短く言えば、検索エンジンは次の役割をまとめて担っています。
- 新しいページや更新されたページを見つける
- ページの中身を読み取り、何について書かれているかを整理する
- 重複や類似ページをまとめる
- 検索語に対して、どの結果を先に見せるかを決める
- 画像、地図、ニュース、動画など、見せ方も切り替える
図書館にたとえると、本棚そのものではなく、蔵書を集める係、目録を作る係、利用者に本を案内する係が一体化したような存在です。
ただし実際の検索エンジンは、紙の目録よりはるかに複雑です。ウェブのページ数は膨大で、しかも毎日内容が変わります。そのため、常に巡回して、古い情報を更新し続ける必要があります。
登場人物と役割
検索結果が出るまでには、少なくとも次の役割があります。
クローラー
クローラーは、ウェブ上のページをたどって見つける自動プログラムです。GoogleではGooglebot、BingではBingbotが代表例です。
役割は単純で、公開ページにアクセスし、リンクをたどり、新しいURLや更新を見つけることです。サイトマップというページ一覧ファイルがあれば、それも手がかりになります。
インデックス
インデックスは、見つけたページの内容を整理して蓄える巨大な索引です。本文、画像、言語、地域性、ページ同士の関係などがここで整理されます。
本のタイトルだけを並べた一覧ではありません。検索エンジンはページの内容を理解しやすい形にしておき、あとで検索語と照合できるようにします。
ランキングシステム
ランキングシステムは、インデックスの中から候補を選び、どの順番で見せるかを決める仕組みです。Googleは、関連性や有用性を判断するために多数の要素を見ると説明しています。
ここでは「検索語にその単語があるか」だけでは足りません。ページの内容、リンク関係、鮮度、地域、言語、使っている端末、検索の意図まで含めて判断されます。
流れで見る: 検索結果が表示されるまで
ここからが本題です。利用者が検索窓に言葉を入れる前から、裏側では準備が進んでいます。
1. ページを見つける
最初の仕事は、ネット上にどんなページがあるかを知ることです。
Google公式資料では、ウェブには中央の登録台帳がないため、検索エンジンはリンクやサイトマップを手がかりにURLを発見すると説明しています。つまり、世の中の全ページが自動で名簿に載る仕組みはありません。
見つけ方の例は次の通りです。
- すでに知っているページのリンクをたどる
- サイト運営者が用意したサイトマップを読む
- 前に見たページを再訪して更新を確認する
2. ページを読み取る
URLを見つけたら、クローラーが実際にページへアクセスします。このとき検索エンジンは、ただHTMLを拾うだけではありません。Googleは、ページをブラウザのようにレンダリングし、必要に応じてJavaScriptも実行すると説明しています。
ここが重要です。いまのウェブサイトは、最初は空に近く見えても、あとからJavaScriptで内容を表示することがあります。検索エンジンが表示後の状態まで見ないと、中身を正しく理解できません。
ただし、読みに行けない場合もあります。
- サーバーが不安定で応答しない
robots.txtで巡回が制限されている- ログインしないと見られない
- ページ設計が複雑で内容を取り出しにくい
3. インデックスに登録する
ページを読めたら、そのまま即表示ではなく、まず整理されます。検索エンジンはページの主題、言語、重複関係、代表URLなどを判断し、検索用の索引に保存します。
この段階で大事なのは、見つかったページが必ず登録されるわけではないことです。Googleも、処理したすべてのページがインデックスされるわけではないと明記しています。
登録されにくい例としては、次のようなものがあります。
- 内容が薄い、または重複が多い
noindexで登録しない指定がある- どのURLを代表にするか判断しにくい
- サイト構造の都合で内容を理解しづらい
4. 検索語に合う候補を探す
ユーザーが検索すると、検索エンジンはインデックスから候補を引き出します。ここで初めて「今の検索語」と「事前に整理した情報」が結びつきます。
このとき見ているのは、単純な一致だけではありません。
- 単語そのもの
- 言い換えや関連概念
- 検索の意図
- 新しさが必要な話題かどうか
- 地域情報が必要な検索かどうか
たとえば「近くの自転車修理」と「ロードバイク おすすめ」では、必要な結果が違います。前者は地図や店舗情報が重要で、後者は比較記事や画像の価値が高くなります。
5. 順番を決めて表示する
最後に、候補の順番と見せ方を決めます。Googleは関連性の判断に多数の要素を使い、位置情報、言語、端末などでも結果が変わると説明しています。Bingも、大量の候補から有用性を予測するために機械学習を使うと案内しています。
ここで初めて、私たちが見ている検索結果画面になります。青いリンクだけではなく、画像、地図、動画、強調スニペットのような表示が混ざるのもこの段階です。
なぜこんな回りくどい構造なのか
検索エンジンが毎回リアルタイムで全ウェブを読み直さないのは、速度と規模の問題が大きいからです。
速さのため
世界中のページを検索のたびに見に行っていたら、結果は一瞬では返りません。先に索引を作っておく方式なら、利用者は短時間で候補を受け取れます。
品質のため
ページを見つける作業、内容を理解する作業、順番を決める作業を分けることで、それぞれを改善しやすくなります。JavaScriptの読み取り、重複判定、ランキング改善を別々に進められるからです。
サイトへの負荷を抑えるため
GoogleもBingも、クローラーがサイトに過剰な負荷をかけないよう調整すると説明しています。検索エンジンは便利ですが、巡回が乱暴だとサイト自体が落ちかねません。だから巡回頻度にも制御が必要です。
身近な例でイメージすると
新しいカフェを検索する場面で考えると流れが見えやすくなります。
- 店の公式サイトや地図情報が公開される
- クローラーがそのページやリンクを見つける
- 検索エンジンが営業時間、場所、内容を整理する
- あなたが「渋谷 カフェ 朝早い」と検索する
- 距離、営業時間、ページ内容、使っている言語などを踏まえて候補が並ぶ
このとき、店が昨日サイトを更新しても、まだ巡回前なら古い情報が残ることがあります。逆に、ページが存在しても登録されていなければ検索結果に出ません。ここに「公開したのに見つからない」が起こる理由があります。
よくある誤解
短く整理すると、混同されやすいのはこのあたりです。
「公開したらすぐ検索に出る」わけではない
ページ公開と検索表示のあいだには、発見、巡回、整理、登録の工程があります。早いこともありますが、必ず即時ではありません。
「お金を払えば自然検索で上に出る」わけではない
Googleは、巡回頻度や自然検索順位をお金で上げることはないと明記しています。広告枠はありますが、自然検索の順位決定とは別です。
「検索結果はみんな同じ」ではない
場所、言語、端末、検索語の意図によって結果は変わります。同じ言葉でも、東京での検索と別の地域での検索では見える店や地図情報が違って当然です。
「クローリングされたら必ずインデックスされる」わけではない
見つけられたことと、登録されることと、上位に出ることは別です。3つは同じではありません。
要点をまとめると
- 検索エンジンの基本構造は「見つける」「整理して登録する」「並べて表示する」
- 速く返せるのは、検索前に巨大な索引を作っているから
- 結果の順番は単語一致だけでなく、意図、地域、言語、使いやすさなども関わる
- サイトが公開されていても、巡回や登録の状態しだいで見え方は変わる
検索エンジンを理解する近道は、「ウェブを直接探している」のではなく「事前に作られた索引を、今の質問に合わせて再配列している」と捉えることです。今後はAI要約や検索結果の表示形式が変わっても、この土台であるクローリング、インデックス、ランキングの重要性はしばらく変わりません。見るべき次の論点は、検索エンジンが何を拾えないのか、そして何を信頼できる情報として上に出そうとしているのかです。