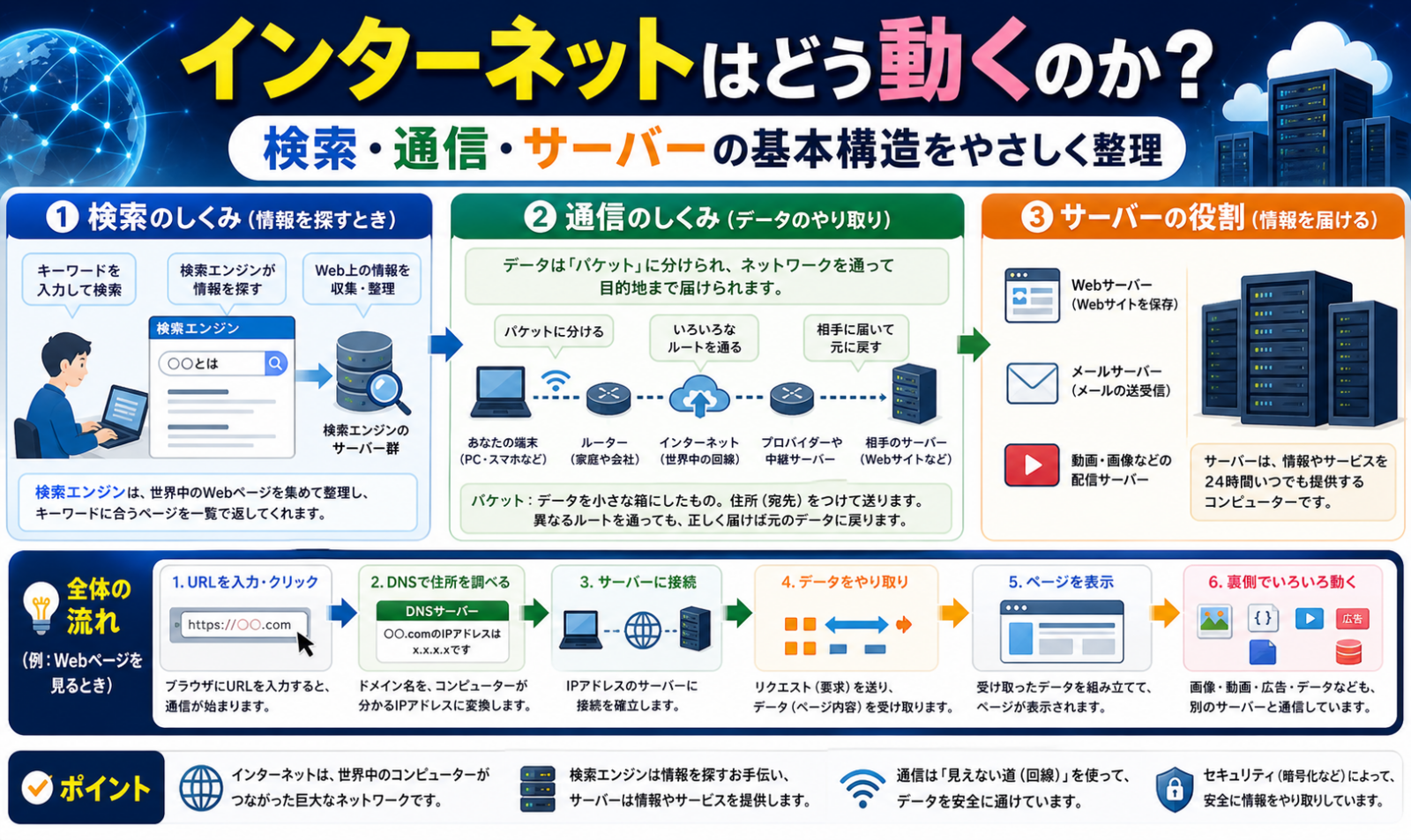
インターネットはどう動くのか? 検索・通信・サーバーの基本構造を初心者向けに整理
インターネットの正体を一言でいえば、世界中の小さなネットワークをつなぎ、共通ルールでデータを受け渡す仕組みです。
私たちが検索して、ページを開いて、動画を見られるのは、1つの巨大サービスが全部を握っているからではありません。住所を調べる役、道順を運ぶ役、安全に届ける役、ページを返す役が分かれていて、それぞれが連携して動いています。
- インターネットは「ネットワーク同士をつなぐ土台」です
- Webはその上で動くサービスの1つです
- 検索エンジンはWeb上の情報を集めて整理し、見つけやすくする仕組みです
- ページ表示はおおむね「名前を調べる → 通信路を作る → データをやり取りする → サーバーが返す」の順で進みます
結局、インターネットはどういう仕組みなのか
まず核心です。インターネットは、端末どうしが直接なんでも分かり合っている世界ではありません。
共通の約束事を重ねて、役割分担しながらデータを届ける多層構造です。人が覚えやすい名前はDNSがIPアドレスに変え、IPが届け先を示し、TCPやQUICが通信の安定性を支え、HTTPやHTTPSが「このページをください」というやり取りを決めます。
ここがポイント: ふだん見えている「検索結果」や「Webページ」は表面です。裏側では、名前解決、経路選択、暗号化、応答生成という別々の仕組みが順番に動いています。
まず区別したい3つの言葉
ここを混同すると、全体像が見えにくくなります。
インターネット
ネットワーク同士を接続する基盤です。IETFのIP仕様は、データを小さな単位で宛先へ届ける考え方を定めています。
Web
ブラウザでページを見る仕組みです。IETFのHTTP仕様では、クライアントがリクエストを送り、サーバーがレスポンスを返します。つまりWebは、インターネットの上で動く代表的なサービスです。
検索エンジン
Webそのものではありません。Web上のページを集め、索引を作り、検索語に応じて候補を並べる仕組みです。Googleは公式資料で、検索が「クロール」「インデックス」「検索結果の表示」の3段階で動くと説明しています。
登場人物は誰か
ページを1回開くだけでも、関わる役は意外と多いです。
- 利用者の端末: ブラウザでリクエストを出す
- ルーター: データを次にどこへ送るか判断する
- ISP: 家やスマホの回線をインターネットへつなぐ事業者
- DNSリゾルバ: ドメイン名からIPアドレスを調べる
- DNSサーバー: ドメイン名に対応する情報を持つ
- Webサーバー: HTML、画像、APIの結果などを返す
- 検索エンジン: ページを集め、整理し、検索語に応じて候補を返す
DNSの基本設計を定めたRFC 1034では、DNSを「名前空間」「名前サーバー」「リゾルバ」の3要素で説明しています。ここを押さえると、なぜ名前を入れるだけで目的のサイトに届くのかが見えてきます。
ページを開くとき、裏側で何が起きるのか
ブラウザでURLを開く流れを、順番に追います。
1. 名前を住所に変える
人は example.com のような名前を使いますが、通信ではIPアドレスが必要です。そこでDNSが動きます。
大まかな流れは次の通りです。
- ブラウザやOSが手元のキャッシュを確認する
- 見つからなければ、契約中のDNSリゾルバに問い合わせる
- リゾルバは必要に応じて、ルート、TLD、権威DNSの順にたどる
- 最終的にIPアドレスを受け取り、端末へ返す
2026年5月3日時点で、ICANNはルートサーバーシステムについて、13のルート識別子と、世界に分散した1,500超の個別サーバー群で支えられていると案内しています。これは、1か所が止まっても全体がすぐ止まらないようにするためです。
2. 宛先までデータを運ぶ道をつくる
IPは、データを宛先まで運ぶための基礎ルールです。RFC 791は、IPがデータグラムを送る役割に絞られていて、再送や流量制御は持たないと説明しています。
つまりIPは「届け先を書く封筒」に近い役です。確実に届いたかの確認までは、別の層が担当します。
3. 乱れや欠落を吸収しながら通信する
ここでTCPなどが効いてきます。RFC 9293では、TCPは信頼できる順序付きのバイト列サービスをアプリケーションに提供するとされています。
これが重要なのは、Webページが1文字ずつバラバラに届いても困るからです。
- 抜けたデータがあれば再送する
- 順番が前後しても並べ直す
- 相手が受け取れる量を見ながら送る
現在のWebでは、HTTP/1.1やHTTP/2は主にTCPの上で動きます。RFC 9110は、HTTP/3がQUICを使ってUDP上で動く形も示しています。初心者向けに単純化すると、「まず運ぶ土台があり、その上でWebの会話が乗る」と考えれば十分です。
4. 中身のやり取りをする
最後にHTTPやHTTPSで、「何をほしいか」「何を返すか」を決めます。
- ブラウザが
GETなどのリクエストを送る - サーバーがHTMLや画像、JSONを返す
- ブラウザが受け取った内容を組み立てて画面に表示する
HTTPSは、HTTPを暗号化して送る形です。TLS 1.3のRFC 8446では、TLSは盗み見、改ざん、なりすましを防ぐための仕組みとして定義されています。URLに鍵マークが出るのは、この保護が働いているからです。
検索はどうやって結果を出しているのか
検索エンジンは、開いてほしいページをその場で探し回っているわけではありません。先に大量のページを集めて整理し、検索時にはその索引から候補を出します。
1. クロール
検索エンジンのクローラが、リンクをたどってページを取得します。
2. インデックス
取得したページの本文、画像、構造などを解析し、巨大な索引データベースに登録します。
3. 検索結果の表示
利用者が検索語を入れると、その索引から関連性の高い候補を選び、順番を付けて返します。
この構造だと、検索のたびにWeb全体を生で巡回しなくて済みます。だから、短時間で結果を返せます。
なぜこんなに役割が分かれているのか
理由は単純で、1つの仕組みで全部やろうとすると、壊れやすく、広がりにくいからです。
分業すると強い点
- 拡張しやすい: サイトの中身が変わっても、IPやDNSの仕組み全部を変えなくてよい
- 障害に強い: 各層で冗長化しやすい
- 世界規模でつながる: 異なる会社、国、回線でも共通ルールで会話できる
- 安全性を足しやすい: 後からTLSのような保護層を重ねられる
DNS、IP、TCP、HTTPが別れているのは、面倒だからではなく、世界中の端末や事業者が同時参加できるようにするためです。
身近な例で置き換えると
完全に同じではありませんが、宅配にたとえるとイメージしやすくなります。
- DNSは「宛名から住所を引く住所録」
- IPは「配送先住所付きの荷物」
- TCPは「足りない荷物があれば送り直し、順番もそろえる管理」
- HTTPは「何を届けてほしいかを書く依頼書」
- サーバーは「依頼に応じて商品や書類を出す倉庫」
- 検索エンジンは「町中の店を調べて索引化した案内所」
ただし実際のネットは、もっと細かく自動化され、同時並行で動いています。たとえは入口としてだけ使うのが安全です。
よくある誤解
「インターネット=Google」ではない
Google検索は便利ですが、インターネットそのものではありません。検索なしでも、URLが分かれば直接サイトへ行けます。
「Web=インターネット」でもない
メール、メッセージ、オンラインゲーム、動画配信もインターネット上で動きます。Webはその一部です。
「サーバーは1台の大きな箱」だけではない
実際は複数台に分散され、CDNやロードバランサーが前段に入ることも珍しくありません。利用者からは1つのサイトに見えても、裏側は分業されています。
「検索結果はその場で全部探している」わけではない
検索は事前収集した索引を使うから速い、という点が重要です。
要点を短く整理すると
- インターネットは、ネットワーク同士をつなぐ共通基盤
- Webは、その上でページをやり取りする仕組み
- 検索エンジンは、Web上の情報を集めて整理する別の仕組み
- ページ表示は「DNSで名前解決 → IP/TCPなどで通信 → HTTP/HTTPSで応答」の流れで動く
- 多層構造なのは、世界規模で拡張しやすく、壊れにくく、安全性も足しやすいから
まとめ
インターネットを理解する近道は、「1つの魔法の仕組み」だと思わないことです。名前を解決するDNS、届けるIP、安定させるTCPやQUIC、内容をやり取りするHTTP、情報を探しやすくする検索エンジンが、それぞれ別の仕事をしています。
この見方を持つと、通信が遅いときに「DNSが遅いのか、回線が細いのか、サーバーが重いのか」、検索結果が偏るときに「Web全体の問題か、検索の索引や順位付けの問題か」を切り分けやすくなります。次にニュースでDNS障害、サーバーダウン、検索アルゴリズム更新という言葉を見たら、どの層の話かを意識して読むと理解が一気に進みます。